Model repeated cross-sectional data
Source:vignettes/repeated_cross_sectional.Rmd
repeated_cross_sectional.RmdAge-time varying model
To monitor changes in a population’s seroprevalence over time, modelers often conduct multiple cross-sectional surveys at different time points, each using a new representative sample. The resulting data are known as repeated cross-sectional data.
Proposed approach
To model repeated cross-sectional serological data,
serosv offers age_time_model() function which
implements the following workflow:
- Fit age-specific seroprevalence for each survey period
- Monotonize age-specific or birth-cohort-specific prevalence over time
- Fit monotonized age-specific seroprevalence for each survey period
Fitting data
The function expects input data with the following columns:
Either
ageandstatus(linelisting) orageandpos+tot(aggregated)A column for date of survey (specified via
time_colargument)A column for id of each survey period (specified via
grouping_colargument)
# Prepare data
tb_nl <- tb_nl_1966_1973 %>%
mutate(
survey_year = age + birthyr,
survey_time = as.Date(paste0(survey_year, "-01-01"))
) %>% select(-birthyr) %>%
filter(survey_year > 1966) %>%
group_by(age, survey_year, survey_time) %>%
summarize(pos = sum(pos), tot = sum(tot), .groups = "drop")
head(tb_nl)
#> # A tibble: 6 × 5
#> age survey_year survey_time pos tot
#> <int> <dbl> <date> <int> <int>
#> 1 6 1970 1970-01-01 140 40868
#> 2 6 1971 1971-01-01 55 17874
#> 3 6 1972 1972-01-01 4 2163
#> 4 7 1970 1970-01-01 328 105960
#> 5 7 1971 1971-01-01 308 96326
#> 6 7 1972 1972-01-01 11 2807The monotonization method can be specified via the
monotonize_method argument, serosv currently
supports 2 options:
Pooled adjacent violators average (
monotonize_method = "pava")Shape constrained additive model (
monotonize_method = "scam")
The users can also configure to monotonize either:
Age-specific seroprevalence over time (
age_correct = FALSE)Or birth cohort specific seroprevalence over time (
age_correct=TRUE)
out_pava <- tb_nl %>%
age_time_model(
time_col = "survey_time",
grouping_col = "survey_year",
age_correct = F,
monotonize_method = "pava"
) %>%
suppressWarnings()
out_scam <- tb_nl %>%
age_time_model(
time_col = "survey_time",
grouping_col = "survey_year",
age_correct = T,
monotonize_method = "scam"
) %>%
suppressWarnings()The output is a data.frame with dimension [number of
survey, 9], where each row corresponds to a single survey period. The
columns are:
column for id of survey period
df- input data.frame corresponding to that survey periodinfo- model for the seroprevalencemonotonized_info- model for the monotonized seroprevalencemonotonized_ci_mod- model for the monotonized confidence intervalsp- predicted seroprevalence of the given input datafoi- estimated force of infection fromspmonotonized_sp- predicted monotonized seroprevalence of the given input datamonotonized_foi- estimated force of infection frommonotonized_sp
out_pava
#> Age-time varying seroprevalence model
#>
#> Input type: aggregated
#> Grouping variable: survey_year
#> Monotonization method: pava
#> Monotonize across: age group
#> # A tibble: 7 × 9
#> survey_year monotonized_info monotonized_ci_mod df info sp
#> <dbl> <list> <list> <list> <list> <list>
#> 1 1967 <gam> <named list [2]> <tibble> <gam> <dbl [5]>
#> 2 1968 <gam> <named list [2]> <tibble> <gam> <dbl [5]>
#> 3 1969 <gam> <named list [2]> <tibble> <gam> <dbl [6]>
#> 4 1970 <gam> <named list [2]> <tibble> <gam> <dbl [13]>
#> 5 1971 <gam> <named list [2]> <tibble> <gam> <dbl [8]>
#> 6 1972 <gam> <named list [2]> <tibble> <gam> <dbl [8]>
#> 7 1973 <gam> <named list [2]> <tibble> <gam> <dbl [5]>
#> # ℹ 3 more variables: foi <list>, monotonized_sp <list>, monotonized_foi <list>
out_scam
#> Age-time varying seroprevalence model
#>
#> Input type: aggregated
#> Grouping variable: survey_year
#> Monotonization method: scam
#> Monotonize across: birth cohort
#> # A tibble: 7 × 9
#> survey_year monotonized_info monotonized_ci_mod df info sp
#> <dbl> <list> <list> <list> <list> <list>
#> 1 1967 <gam> <named list [2]> <tibble> <gam> <dbl [5]>
#> 2 1968 <gam> <named list [2]> <tibble> <gam> <dbl [5]>
#> 3 1969 <gam> <named list [2]> <tibble> <gam> <dbl [6]>
#> 4 1970 <gam> <named list [2]> <tibble> <gam> <dbl [13]>
#> 5 1971 <gam> <named list [2]> <tibble> <gam> <dbl [8]>
#> 6 1972 <gam> <named list [2]> <tibble> <gam> <dbl [8]>
#> 7 1973 <gam> <named list [2]> <tibble> <gam> <dbl [5]>
#> # ℹ 3 more variables: foi <list>, monotonized_sp <list>, monotonized_foi <list>For visualization, the plot function for age_time_model
offers the following configurations
facetwhether to visualize result for each survey period separately (facet=TRUE) or on a single plot (facet=FALSE)modtypechoose which model to visualize, the model fitted with input data (modtype="non-monotonized") or monotonized data (modtype="monotonized")
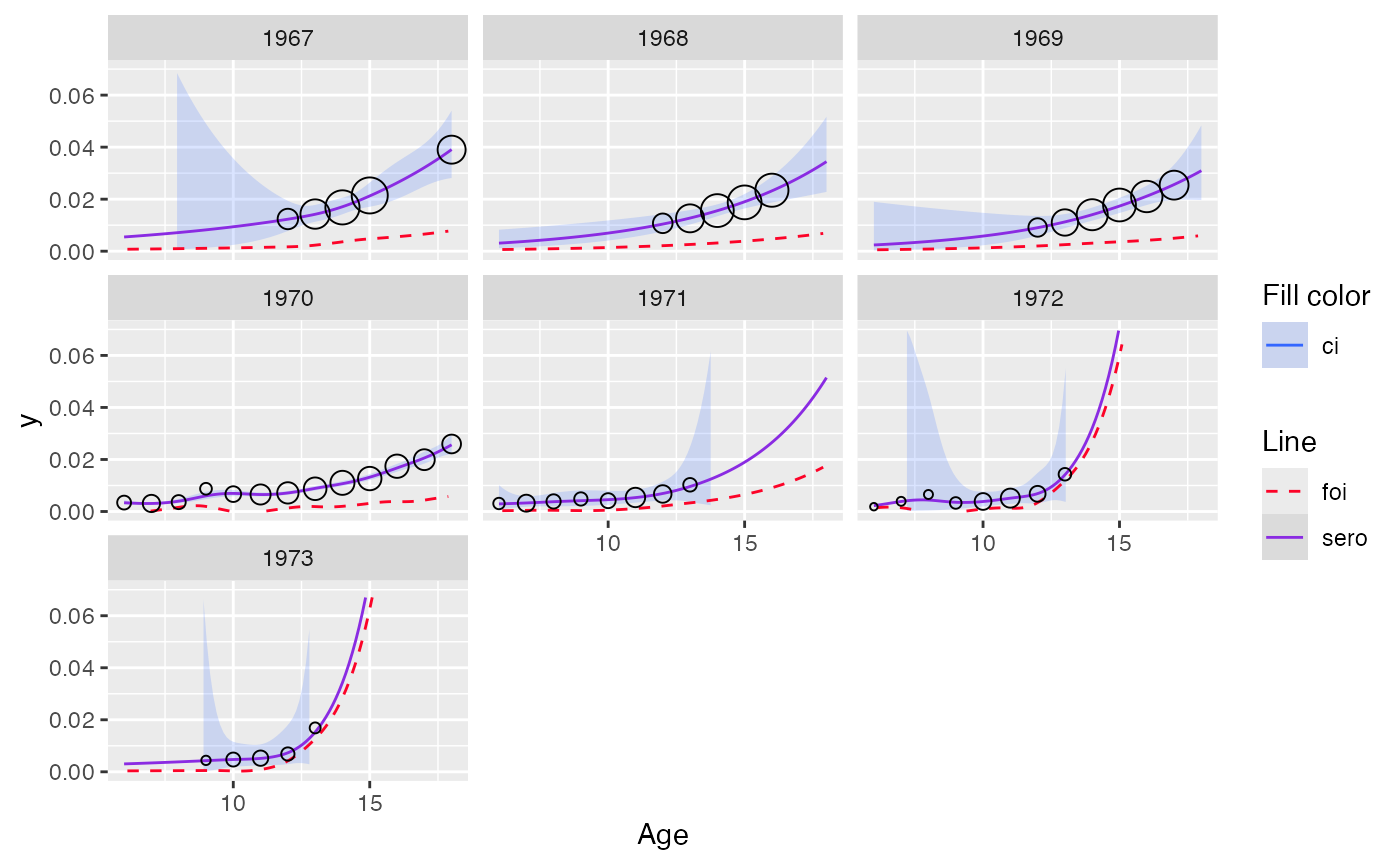
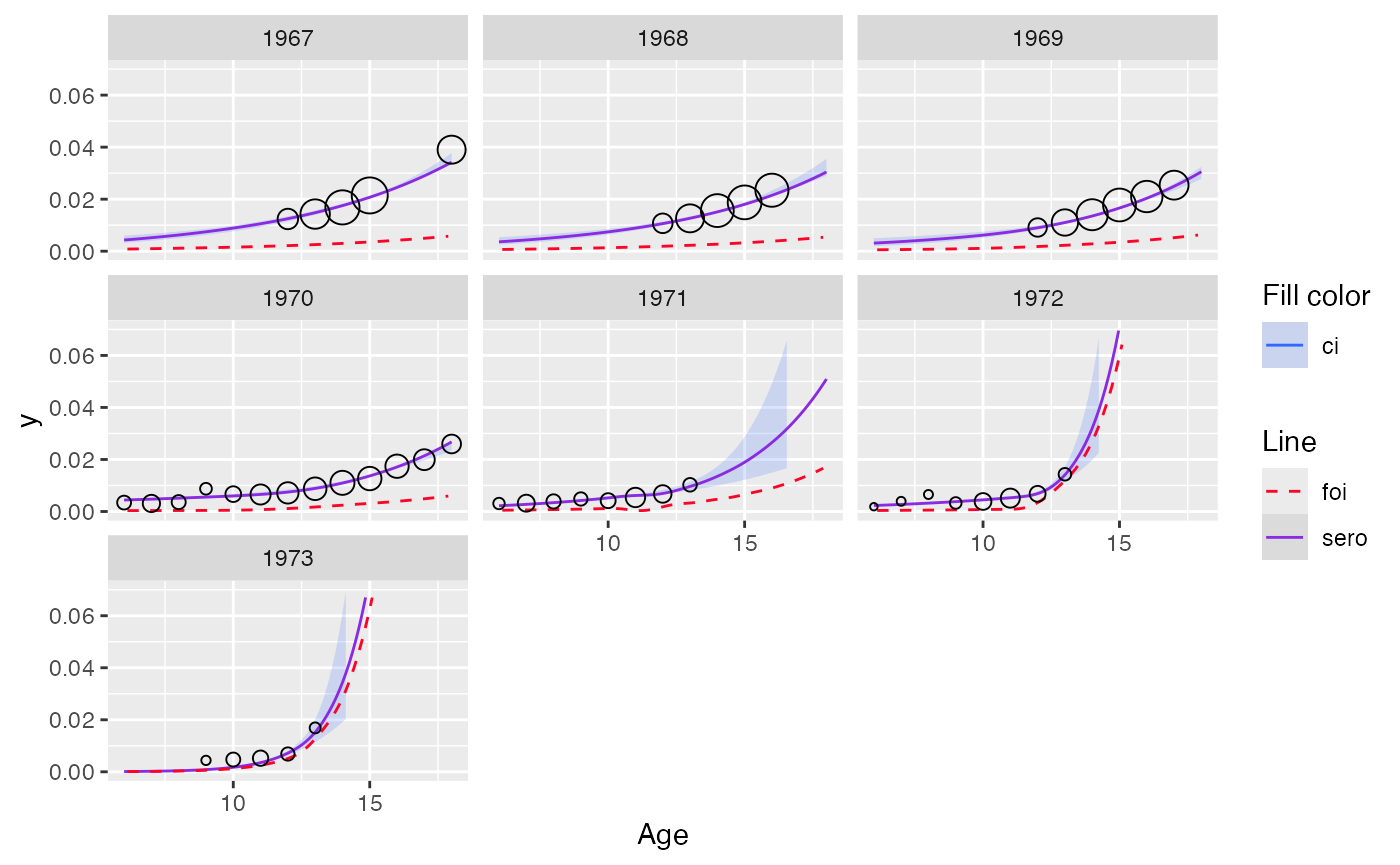
Example: output for model with PAVA for monotonization
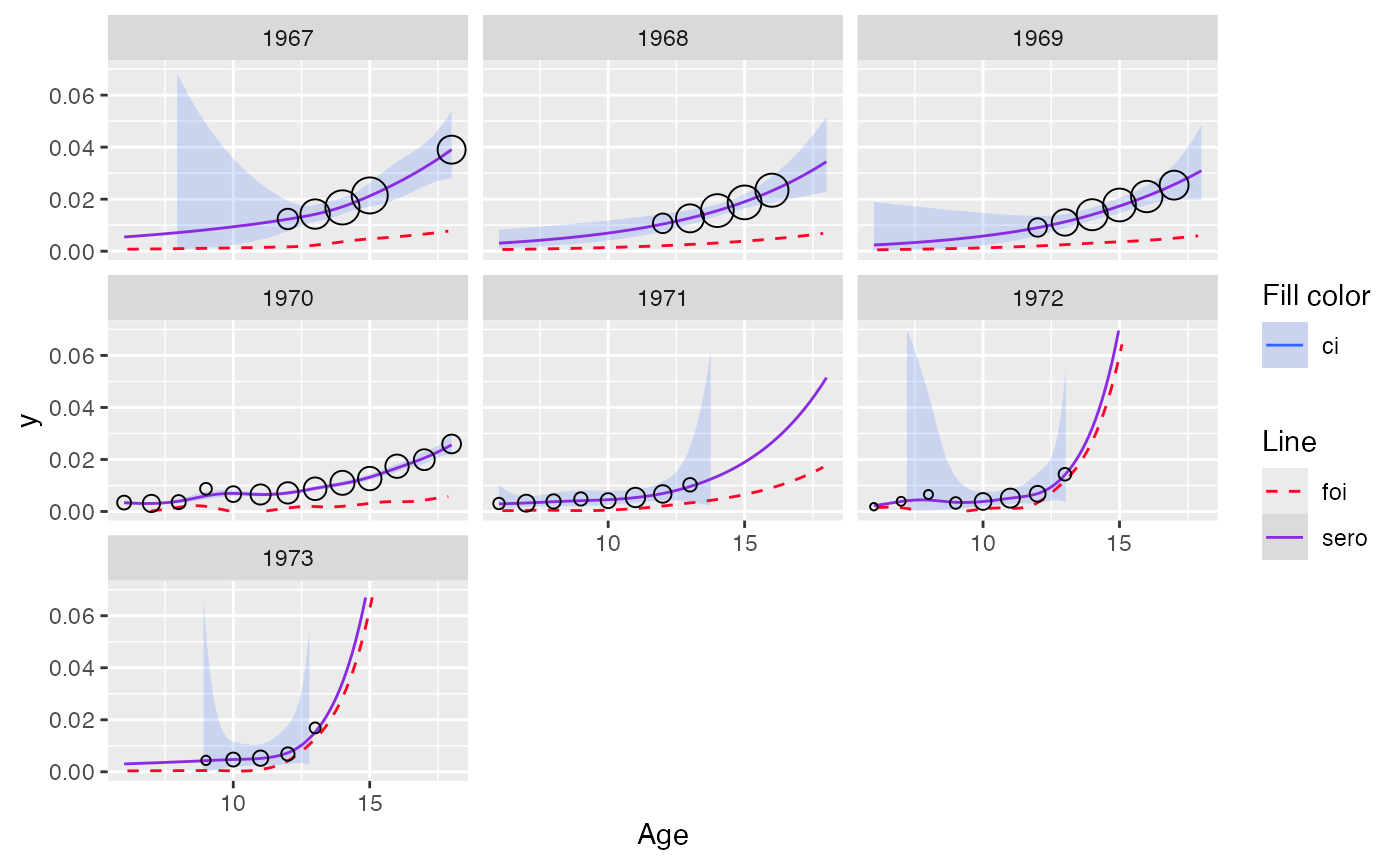
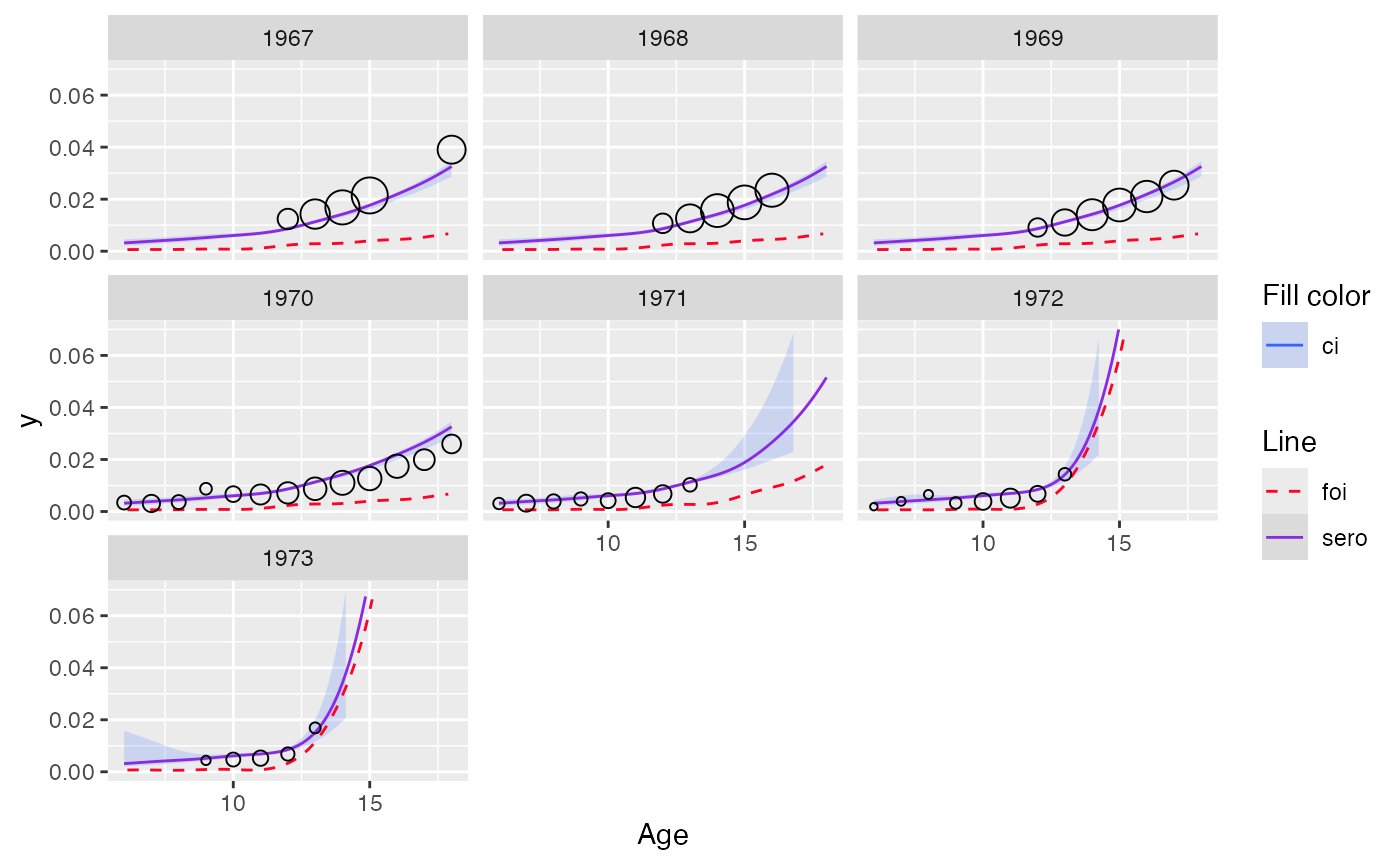
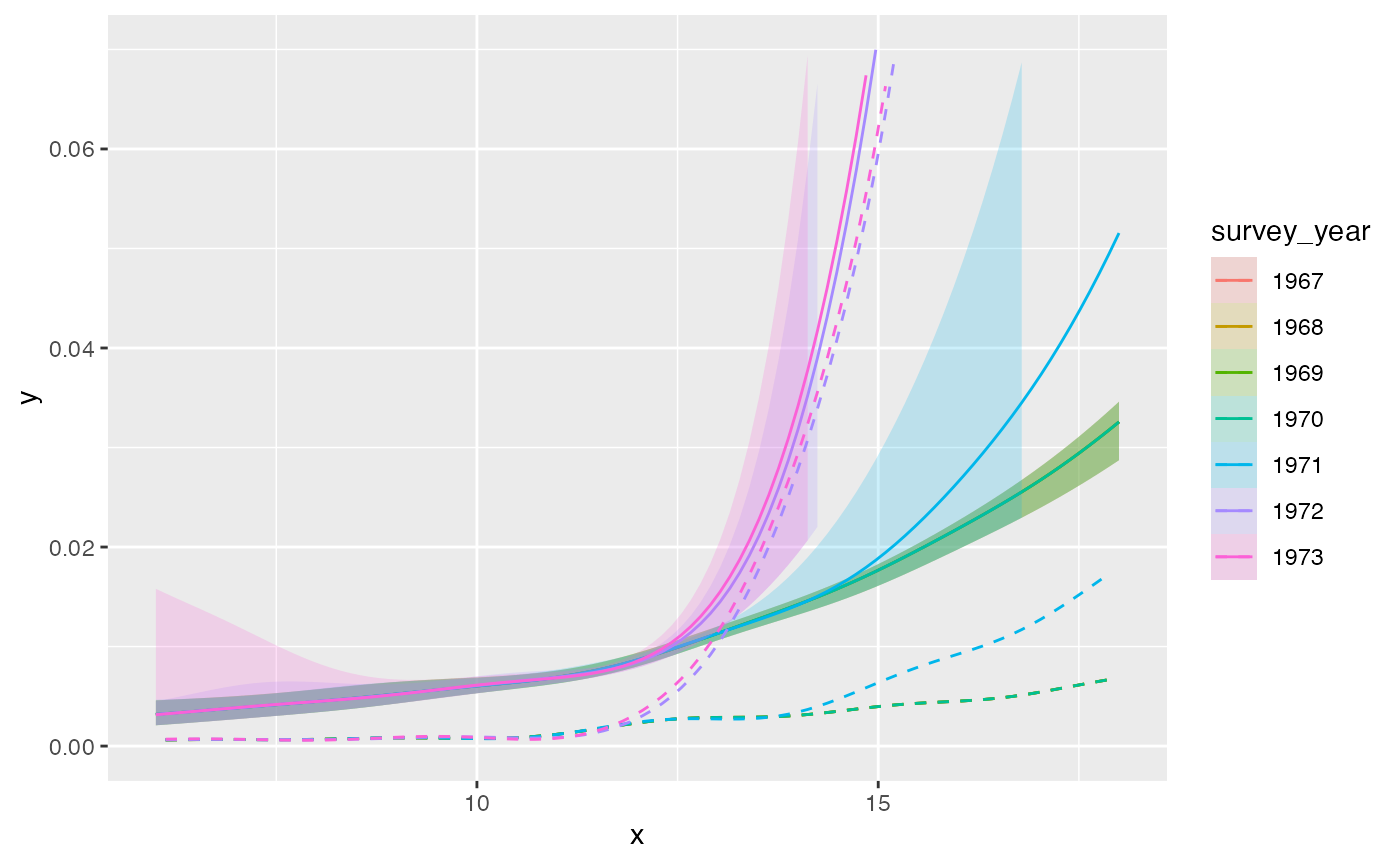
Example: output for model with SCAM for monotonization